Some of the code I write is Open Source, but these days most of it is closed source and property of Moodstocks, the startup I work for. For the last three years I have had the chance to work on a lot of really interesting projects, the most significant of which I will talk about now. If you are still a student, maybe that can inspire you to join a startup. Maybe you will even decide to join us in our quest to advance mobile image recognition and applications in general.
When I joined Moodstocks in April 2010 the team was working on a mobile price comparison application called Pikadeo. The pitch was that you could take a picture of any cultural product (CD, DVD, book…) and it would give you a list of places where you could buy it, sorted by price.
The iOS application itself, largely designed by Louis Romero who had interned at Moodstocks and left just as I arrived, was working. The image recognition technology was working too, although it was purely server-side. The team was already researching how to leverage client-side processing but it was really just a crazy idea at that point, so Pikadeo was doing what most “mobile” image recognition software still does: send JPEG frames to the server.
What was missing was the data. We needed to crawl several large e-commerce websites, extract product images and metadata, send the former to the image recognition engine and the store the latter in a database. So I set out to write a crawler in Ruby, which was the dynamic language of choice of the team at the time. Moodstocks was a Ruby / C++ shop due to the background of the founders. Obviously things have changed a lot since then.
I tried to use Hadoop for the job, mostly because it was trending at that time and I had access to Amazon’s Elastic MapReduce. I soon understood that 1) the Hadoop Streaming interface was not quite there yet so I would have to switch to Java and 2) the Map/Reduce paradigm was not the best for the job anyway.
After reading a few papers on crawling (I had to anyway, since that project would be the basis of my MSc thesis, but it actually helped a lot) I ended up writing a kind of Master/Worker system, with work queues in Beanstalkd and metadata storage in Amazon’s SimpleDB, which did the job. It did the job a little too well, actually, since it ended up DDoSing an e-commerce website for a few seconds during a performance test for my thesis. Fortunately I was monitoring it and hit the stop button…
After setting reasonable speed limits and balancing the requests between various websites, Harvest was fast enough for our needs. The bottleneck became the image search engine itself, I will expand on that later.
Due to the deprecation of the Pikadeo product, Harvest is no longer used today. It is probably a good thing: it was my first Ruby program so the code was awful, it was way too complex and too tied to AWS (the master instance would run and kill worker instances, it relied a lot on SimpleDB…). That being said, the crawling model was sound.
Once we got crawling sorted out, the image recognition engine itself became the problem. Oak (it has become a tradition to use plant-related names for our projects internally) had been almost entirely written by Cédric, Moodstocks’ CTO. It was a piece of C++ software, with the image recognition parts isolated in dynamic libraries and a Thrift layer to interface with the core Ruby on Rails Web application. It was multithreaded, designed to run on a single multicore EC2 instance.
The scalability pain point, it turned out, was not CPU load. The index was stored in a B+ Tree in Tokyo Cabinet, a tool we like a lot and still use today in other parts of our system. The problem was that when we indexed millions of images the dataset would inevitably become very large, larger than the available memory. The system would still be very responsive on most reads, but writes would invalidate large chunks of the in-memory cache and result in long pauses.
Latency is the enemy when you write image recognition software, so we decided not to sacrifice it: all the index had to fit in RAM. We decided to consider RAM as our primary datastore. That decision would bring about our later choices.
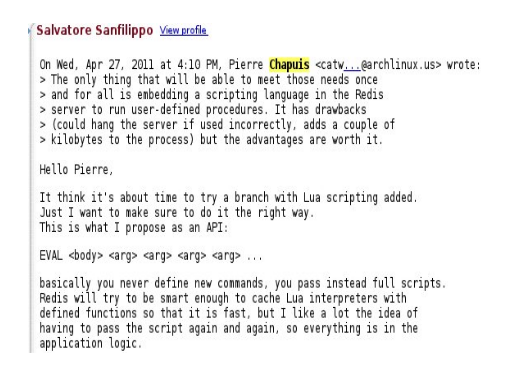
Since rebuilding an index can be very long we wanted something that could persist even if the engine crashed or had to be restarted for an update. Soon it became obvious that Redis could be the answer. However it was missing some commands that we needed, especially one that would insert the same key with different values in different maps (if you have already written inverted indices you may understand why, otherwise have a look at that presentation). Lua scripting was what we needed, but it wasn’t there yet so I ended up forking Redis to develop it in C while lobbying for scripting support. Acorn was, to my knowledge, the first application to run Redis 2.5 in production, and the first one to use Redis scripting too. We never encountered any Redis-related crash.
Now, to have the index fit entirely in RAM, we would have to distribute it across different machines, so Acorn would have to be a distributed system. Knowing that, I chose to make Acorn nodes single-threaded: they would communicate by message passing and we would have several of them per instance.
We chose MessagePack for serialization of Redis values, and I started looking at MessagePack-RPC. It had a lot of the pieces that I wanted for the distribution part, and one major problem: it was only usable in Ruby. But we were not CPU-bound… Would it be sensible to write the engine in a dynamic language? I started investigating that possibility. Our C++ libraries already had Ruby bindings that we used for vision R&D, and the little number crunching Oak Core did (mostly different scoring algorithms) turned out to be fast enough in Ruby.
So Acorn ended up as a distributed system written in Ruby, with MessagePack-RPC for communication and a fork of the development branch of Redis at its heart. It used MessagePack-RPC for communication with our Rails stack too.
In retrospect, relying on two unstable pieces of software was risky. It turned out well, and Redis was definitely the right choice, especially since Lua Scripting now allows us to use a regular, stable 2.6 version. 0MQ would probably have been a better technical choice than MessagePack-RPC, and plain C better than Ruby, but I believe those choices saved us development time, and time to market was important. Acorn is still in production today, doing its job for legacy clients who use online recognition.
You now know that when I joined Moodstocks it was trying to be a B2C company. However we were seeing interest in licensing our technology, and began to envision a B2B product: Moodstocks API.
When you write an API, especially as a product, you must write applications for it simultaneously. They serve two purposes: demonstrate what your API can do, and help you figure out how it should be improved. We set out to do that with two mobile applications, one of which was Notes.
The original idea I proposed was, I think, simple: Google SideWiki (RIP) for the real world. That is: you walk in the street, you see something interesting, you take a picture of it, you get a comments thread. If you are the first to do so, you get to leave the first comment (yay, first!!1).
As we were looking to add virality to it, that idea developed into a kind of mostly mobile social network where both people and objects could be followed. Objects actually had their own timeline with an associated Atom feed, which you could reach by browsing or, of course, as the result of an image search.
Technically the server-side part of Notes was a rather classic Sinatra application. The most interesting part of it was that it used some kind of CQRS architecture with all reads coming from Redis and all writes going to log-structured storage. The very nice thing about it was that any part of it could be replayed so it was almost trivial to reproduce bugs or replicate production incrementally to a development setup.
The iPhone application, on the other hand, was one of the nicest and most complex ones we have ever written. I wasn’t responsible for it so I won’t get into details here but the latest internal version we never actually released was IMO a thing of beauty.
As it turned out, Notes got a reasonable amount of online press after our CEO showed it to Michael Arrington at the Le Web conference. This got us a few users and we briefly thought about making it a product in its own right. I wrote a wxPython GUI to analyze logs, trying my hand for the first time at techniques like cohort analysis.
Eventually we took the decision not to invest more time in the idea: we were a small team and our now core B2B business needed our attention. Notes’ success was a long shot and would have required significant time and money investment so I guess it was the right decision, although I would love to see someone revisit the idea.
As I said, Notes was written to help us design our API. Using its feedback and that from the few users of our v1 API, which was more some kind of beta, I set out to write version two.
I will not expand too much on all its aspects here, REST-ish API design being well covered in the literature and online (start here).
The main differences with API v1 were the use of JSON instead of XML, and the ability to index a single image by uploading it to the API using multipart post. Previously, users would upload a XML list of image URLs and associated IDs; we would download them and tell you when indexing was over. Now users index single images and changes are taken into account instantly. The necessity for that was a lesson from Notes and user feedback, and it was made possible by Acorn.
Another interesting choice was the authentication method, HTTP Digest, which we kept from version one. Theoretically, it had all the right properties and was a standard, so it was the best choice. What we had not realized is how many implementations were broken or incomplete (i.e. not supporting nonce reuse, which is a necessity on mobile to reduce the number of HTTP requests). I ended up having to submit patches to a lot of them, and I am not even mentioning .NET land… If I had to do it again today I would probably go with Basic Auth and SSL.
Earlier, I wrote about how I had made Acorn processes single-threaded. This had some advantages, but also a big inconvenient.
Part of the image search process involves quantizing features, which means associating vectors in a many-dimensional space to integers. To do this the curse of dimensionality forces you to use an approximate nearest-neighbor search algorithm.
The way it works is: take a large number of features from a representative dataset and use some kind of clustering algorithm (e.g. k-means) on them to obtain a bunch of centroids (a “vocabulary”), then process these centroids to obtain a datastructure called kd-forest which will be used to perform nearest-neighbor search (a “dictionary”).
Vocabulary generation is clearly an offline task that requires a lot of number crunching and is done as little as possible. Generating the kd-forest, on the other hand, takes from a handful of seconds to a few minutes depending on the size of the vocabulary, so it is frequently done on engine startup. The kd-tree itself only exists in RAM.
The problem with that was that a kd-forest is a rather large datastructure. In our case it occupied hundreds of MB of RAM and took about one minute to generate. That was OK with Oak, where it was shared between threads, but with Acorn that overhead had to be paid for every process, both in space and time. We had to find a way to share the kd-forest across Acorn nodes on the same machine, and if possible to make startup faster.
The solution I opted for was to rewrite the whole quantizer. Previously we had been using popular Open Source libraries for this, but they didn’t do what I wanted.
I wrote the kd-forest generation algorithm as a LuaJIT program. It was the first Lua program officially used in production at Moodstocks, although as you will see it was only run offline. What it does is take centroids as input, generate a kd-forest and serialize it in a way easily readable in C thanks to the FFI. It can also actually perform nearest-neighbor searches but this is only used for test purpose.
Once the kd-forest is serialized, it can be loaded into system shared memory quite fast. A C library can then be used in every Acorn process to access this shared memory read-only and perform nearest-neighbor searches.
The idea is simple once you stop under-estimating the capabilities of SHM on Linux. By default it usually limited to a few MB so you have to increase it a lot for this to work (it can be done with sysctl). The implementation, on the other hand, is far from trivial. My code uses a lot of pointer arithmetics, I should probably clean it up someday, but in the meantime it does its job perfectly.
The Acorn Quantizer was the last major improvement to our online search stack. Around that time, we resolved on a major technological shift: we would perform image recognition on mobile devices directly instead of doing it on the server. Of course, initially, we would have an hybrid approach where on-device recognition would work as a kind of cache, but the mobile was where we would focus our efforts.
Doing on-device image recognition, though, almost meant starting from scratch: we had to make different technological trade-offs, use very different algorithms, and that meant writing an almost entirely new image recognition stack. We named that project Seed.
Seed encompasses a lot of things now, but at its core are proprietary Computer Vision algorithms that we set out to develop with Cédric and Maxime, who had joined us by then. We would discuss them as a team, then Maxime and Cédric would implement them in C while I would work on a Lua version.
The big picture is that some processing is done on the server at indexing time to generate signatures which are then sent to the client. Server-side software used to be entirely Lua, client-side software entirely C, but we decided to implement the whole stack in both languages. I think that was one of the best ideas we ever had. Being able to compare results avoided errors on both sides (tricky things like off-by-ones were always noticed thanks to the fact that Lua is 1-based, floating-point math issues were found…). Lua allowed faster prototyping on some parts and it was interesting to compare the different architectural choices we were making.
With the current (second) generation of the Seed algorithms, we are actually mostly using the C implementation through the LuaJIT FFI on the server side now. That is because I have been working on other projects while the rest of the team (which is not as comfortable with Lua) was developing them, so I would have been a bottleneck if we had kept the dual stack approach. I may well bring the Lua branch up to date someday though, who knows?
Moodstocks’ server-side architecture is some kind of SOA. That means we have a lot of different services that run as daemons and need to stay up. chksrv is a medium-sized program in Bash that takes care of this. It is deployed on every instance with a configuration file that indicates which services should be running on that instance, and it makes sure that they are (correctly). It also checks if other instances are up. If something goes wrongs, it warns the “ops team”, who is basically me and Cédric as a backup in case I am not available.
chksrv is a very useful piece of software but I was a bit worried by its growth as we added services. Standardizing the way we deamonize processes helped a lot with that by increasing code reuse (thank you libslack).
chkcoherence is the ideal complement to chksrv: where the latter checks if services are running, the former verifies that they are doing things right. It is also written in Bash at the top level. I have already written about its concept here.
Anemone is the project that deals with everything related to metrics and measurements at Moodstocks. It is written in Lua and has quite a few different roles:
It also has a web-based dashboard for the team with high-level KPI, written in JavaScript and flot. Someday I might integrate Brett Slatkin’s Cohort Visualizer into it.
I said earlier that with Seed we generate image signatures on the server and send them to the mobile clients where they are used for recognition. Dandelion is the code name of the service responsible for that.
It turns out efficiently sending millions of image signatures per day, over slow and unreliable networks, to devices everywhere in the world, is not trivial. So Dandelion, more than software, is a synchronization protocol and its implementation; a range of tricks to make the best of mobile networks packaged as software. It is one of the reasons (along with all the innovation on CV algorithms and their optimized client-side implementation) why we can propose client-side recognition with databases of thousands of images or even videos, an order of magnitude more than our competitors.
The server part of Dandelion is written in Lua and depends on pieces like Redis and Beanstalkd, which is why I wrote haricot.
Finally, Physalis is the project I am currently working on. It has not been released yet so I won’t get into the details, but I can explain the reasoning behind it.
While we were building Dandelion and through our experience with our clients, we learned the following things:
So we thought: we have done it, why not make it accessible to everybody? This is what Physalis is: Moodstocks’ image signature distribution system generalized so that you can leverage it for your own mobile application.
Physalis will be available in private alpha for selected users soon, under its real brand name (Physalis is only its “internal plant-themed name”). If you are interested in trying it out, get in touch. The requirements are that you should be making a mobile application and ready to communicate on a regular basis with us: we are doing this alpha to collect useful feedback.
EDIT: Physalis was eventually released in August 2013 as Winch.
{kind=link}